It's Not a "Nitpick" if You're Wrong
A Field Guide to Getting Told Off by a Robot
If you engage even a little bit with AI-originated code reviews, you’ll probably hear the word “nitpick.” CodeRabbit not only has a setting that explicitly advertises the suppression of “nitpicks,”
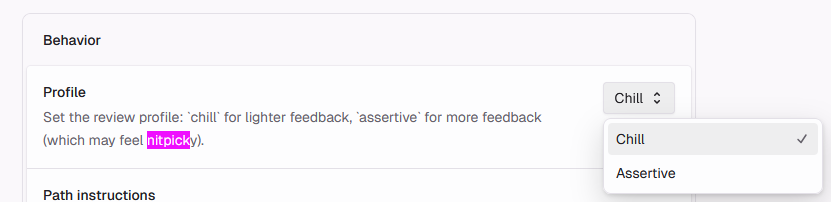
but the reviews it emits explicitly classify and collapse some findings under that label:
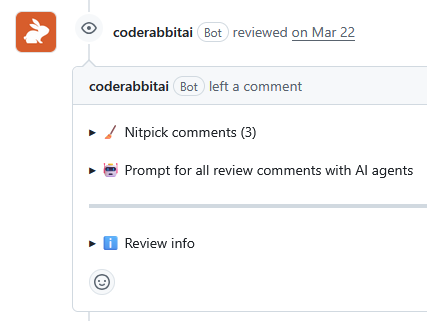
When I was first setting up CodeRabbit, I of course set it to “Chill” mode because who wants nitpicks on their code reviews? I’ll just take my quality feedback, thank you very much.
But, I’m a curious person. Despite the nitpicks being suppressed and hidden, I still peeked at them from time to time. Every time I peeked, they, uh… were actually pretty accurate issues. Dang, I should fix those. When you add up the “normal” findings plus the “nitpick” findings on an AI review of an AI PR, it can sometimes be a lot…
My solution was to whip up a couple prompts to handle PR feedback. And though not all findings always end up fixed in the PR at the moment, they - including the “nitpicks” - are usually valid issues that should be fixed sometime soon.
At my workplace, we also have an AI reviewing code - reviewing pull requests - a custom thing that isn’t CodeRabbit. It, too, tries to rank the severity of feedback and there is a section of low-severity findings that could maybe be called nitpicks, though it doesn’t call them that.
The other day, a coworker referred to that AI’s review as a “nastygram,” a fun and severe word that stuck out enough to give me pause and get me thinking. That dynamic - of the AIs “nastygramming” human engineers - is definitely not a good thing. Is that what was happening here, or was my workplace’s reviewer just as correct and thorough as CodeRabbit in my personal life?
It Was Just Bad Code#
So I went and read it. Four findings, spread across the better part of a printed page. A page is a lot. But it was four problems, each one explained with care. Here’s the shape of what it caught (abstracted, because the code isn’t mine to publish):
- A docstring that described a different algorithm than the one in the function - because the function had implemented a different, less-correct algorithm. The prose faithfully documented what should’ve been written, not what was.
- A test whose fixture was a live, shared resource instead of an isolated test-only fixture, so the test would break the day anyone changed that resource for unrelated reasons. A test that fails for reasons unrelated to what it’s testing is a test you’ll soon learn to ignore.
- A document that declared one canonical URL and then used non-canonical variants of it further down - a spec that won’t follow its own rule inside its own body.
- A cleanup step that instructed running
rm -rfon a shared dot-directory under~, not just the files it had created. The instruction for “leave no trace” was written as “burn down the house.”
None of those is a nitpick. The mildest is a document that argues with itself; the worst is an rm -rf pointed at a directory other processes’ data lives in. Leave them be and you ship a wrong algorithm, a test that cries wolf, a spec no one can trust, and a footgun aimed at a home directory.
Is that really a “nastygram?”
The Models Got Chattier#
At work, I know which models get used under the hood for the reviewer; with CodeRabbit I don’t manage it directly. At work, Opus 4.6 was already a little bit “nitpicky,” but Opus 4.7 and Opus 4.8 bumped the “nitpick” count from around ~3 per PR to 5-10 per PR. It’s getting genuinely noisier.
But… they’re not wrong. They’re just more-thorough than before.
The Pull Request Was Always a Contract#
The findings are legitimate, and legitimate by construction, not by luck. Remember what a pull request is for.
A pull request is a contract. The diff, the description, the tests, the linked context - that bundle is the complete universe of what a reviewer is entitled to consider, and the submitter’s job is to make that universe sufficient. The reviewer’s job is to drill into anything that isn’t obviously correct, and that implies that they first need to drill into any part of the information package that isn’t complete. Failing that precondition would risk the correctness of every subsequent review judgment.
That’s the ostensible procedure, anyway.
Humans honored it loosely: charitable skimming, “I trust this person,” a glance and an LGTM. Or an in-depth review if they’re really feeling it, or a nastygram if they’re really not feeling it.
The machine honors it strictly. What people are calling “nitpicking” is the gap between those two enforcement levels… not actual nitpicking.
The Diplomacy Was Never Free#
Strict enforcement takes the human cushioning away, and that cushioning was never free.
Human review ran on diplomacy, and the diplomacy was carrying a cost very hard to price accurately: it was distributed unevenly. Some people got nastygrammed and some people got grace, and which one you got had less to do with your code than anyone liked to admit. When Google measured “pushback” across its own code reviews, the odds tracked the author’s seniority, tenure, age, and demographics, not just the diff1 - a change from an engineer 60 or older drew more than three times the pushback of an identical-level 18-to-24-year-old. Eye-tracking catches reviewers scrutinizing low-reputation authors’ code harder than high-reputation authors’2 without realizing they’re doing it. The machine reads everyone with the same eyes, including me, especially on the days I cut corners.
Whether that flat gaze feels like fairness or feels like cruelty depends entirely on which side of the old inequality used to subsidize you. If you were a junior getting torn apart by a senior who was bored, or anyone whose work got extra scrutiny for reasons that had nothing to do with the work, the impartial reviewer is the best thing to happen to your feedback in years. If your code used to sail through on a relationship, the impartial reviewer is exposing a subsidy you didn’t know you were collecting.
Aside: Yeah AI Reviews Can Be Wrong#
I’m not trying to pretend that all AI reviews, ever, are perfectly-correct. You can absolutely wire up a dumb AI, dumbly, and get bad reviews.
That is not what I am looking at or talking about here. I have manually inspected, at length, both the CodeRabbit feedback and my workplace’s reviewer’s feedback and they are majority good and correct. This isn’t a fully-mature product space but it’s getting there and the AI reviewer that “nastygrams” you with 15 valid findings will eventually show up in your workflows.
You don’t have to take my two audits for it; the internet is replete with similar stories:
- (July 2025) Swagata Acharyya watched a team roll out AI review and found it “surfaced our shortcomings - bias, fatigue, politeness theatre, vague feedback, and gatekeeping.”
- (September 2025) Lychee tracked every CodeRabbit comment across a month of pull requests, the largest bucket by far was genuine quality improvements; actual nitpicking was about a fifth of the total.
- (April 2026) Alexey Pelykh documented an AI reviewer catching real security vulnerabilities - a sudo bypass, a token exposure - in pull requests experienced humans had already approved.
False positives are real; the reviewer is not infallible and I’m not claiming it is. The claim is about the bulk of the findings, and the bulk of the findings are right. Welcome to the future!
It Was Always This Bad (And That Was Fine)#
So the code was bad. More damning than today’s nastygram is the realization that it was probably always this bad. You just never had a reviewer willing to find every way it was broken, which was fine because you wouldn’t have fixed all of it, anyway.
But, that was reasonable. When a human is the rate limiter, you can only develop at 1x speed. Finding every defect and fixing every defect cost real hours you didn’t have, so you triaged by neglect: fix what’ll hurt, let the rest ride, ship it. That was just prioritization - triage - not negligence. The reviewer who’d have caught everything would have cost more than the bugs they caught, so keeping that sort of person on staff wasn’t in vogue and the code rode out the door with its warts intact and a polite human signature on the bottom.
The Clock Broke#
Then the clock broke, and the excuse went with it: review-and-fix runs faster than 1x now. Hand the reviewer’s findings to a coding agent and it churns through all of them, fixing most for a few dollars and a few minutes - a rounding error against what the manual version used to cost in senior attention. So the trade that made “let it ride” reasonable - thoroughness or shipping, pick one - isn’t a trade anymore. You can review all the things and fix all the bugs and still ship today. Inside a change you’ve already decided to make, accomplishment is now cheaper than discernment.
And now, the people still letting it ride are running on an excuse that expired.
Two Ways to Be Wrong About a Real Bug#
We built a tool that finds bad code and tells the truth about it, and the truth turned out to be unflattering, so a lot of people decided the tool was broken. It isn’t. It reads me the same way it reads everyone, and it caught me, and I fixed it and shipped and said thank you.
The reviewer didn’t lower anyone’s standards or make anyone’s code worse, it just stopped grading on a curve. The discomfort people are reporting as “nitpicking” is mostly the lurch of realizing how generous the curve used to be. Consistency reads as cruelty only to whoever the old inconsistency was sparing.
The tools - at least the ones I’m interacting with - reliably surface real defects. We’ve established that. Which means that when someone gets a finding and rejects it, there are only two roads to that rejection.
They didn’t look: they saw the length of the review and reached for the mute button without checking whether the findings were right.
Or they looked and didn’t recognize a real defect as such. Neither is the kind of thing you want to be SOP on your team. When it happens once it’s a bad day, but when it keeps happening to the same people, pull request after pull request, with no loop and no recovery and no acknowledgment… it stops reading like a bad day and starts reading like a signal.
The prescription, if you want one, is
Git Gud#

Like all git-gud advice, it is perfectly useless to anyone who needs it. Anybody capable of taking it took it already. The slightly-more-useful version (given in full below) - write tighter pull requests, run the loop, make sure you and your agent learn from your mistakes - only works for someone already disposed to do it. The advice requires being the kind of person who’d follow the advice. That recursion isn’t a flaw in the prescription. It’s the diagnosis.
So, maybe it’s for you. Maybe this is your “a-ha” moment, your wake-up call that you’ve got to step up your game. Maybe you just needed a prescription, and you’ll be right as rain in a jiffy. Hopefully, your peers in similar situations can be similarly cured.
The Actual Prescription#
Fix the bugs and write more code that is good.
To “Fix the bugs,” just feed the reviewer’s feedback into a coding agent in a loop until the findings flatten to nothing. This’ll cost a couple bucks at most. Heck, you can even do it yourself like I did at first, a task I like to call “working.”
If you’ve ever run a linter with --fix and committed the result, you already understand the entire technique.
I just swapped the linter for an AI reviewer and swapped autofix for a Wiggum loop, which I run as a slash command because it’s the same prompt every time. Same thing. Lint, autofix, commit. Review, loop, submit.
As for “write more code that is good,” well, you and/or your AI agents need to reflect on what keeps turning up in the reviews. Are you constantly missing documentation? Knock that off; start submitting documentation as part of your PRs. Is your agent constantly reaching for an OSS library when your company uses an in-house one instead? Write the right rule so it doesn’t.
This iterative loop - whether literal or procedural - is the core of the entire collaborative code-writing process, really. It’s not new, it’s not special, it’s not unique to AI. It is what separates getting flagged from staying flagged. Everyone gets flagged. I get flagged constantly. The difference between my pull requests and my coworker’s nastygrammed ones is nothing except time: my first drafts are a mess, too. But I iterate, rinse, repeat, and eventually offer up something polished before I ask my human coworkers to look, because I use the quality-assurance tools in the quality-assurance loops they belong in.
Simon Willison puts the bar plainly: your job is to deliver code you’ve proven to work, and shoving an unreviewed pile at someone else to vet just makes your cleanup their problem. The loop is how I do my proving before I spend a coworker’s attention.
Did you know CodeRabbit has a VSCode plugin so you can get the nastygram right in your IDE before you even push your code to the remote, let alone open a PR? I wager they’re not the only code quality tool that you could, I dunno, use before asking for a code review!
-
“The Pushback Effects of Race/Ethnicity, Gender, and Age in Code Review”, Emerson Murphy-Hill et al., Communications of the ACM, 2022. https://cacm.acm.org/research/the-pushback-effects-of-race-ethnicity-gender-and-age-in-code-review/ ↩
-
“How Do Developers Review Code? An Eye-Tracking Study”, https://dl.acm.org/doi/10.1145/3643916.3644425 (pdf) ↩