Do LLMs Understand "For Each"?
You have a list of items. You need a language model to process each one the same way. Do you write this:
For each item in the list, perform steps 1 through 5.
Or this:
Item 1: Perform steps 1 through 5.
Item 2: Perform steps 1 through 5.
Item 3: Perform steps 1 through 5.
The first is compact, elegant, and how a programmer would think about it. The second is verbose, redundant, and feels like it insults the model’s intelligence. The research says the second one works better, and the reasons are architectural - rooted in how transformers allocate attention. But whether that architecture actually constrains you depends on how, exactly, you harness the models and what, exactly, you ask them to do.
The Curse of Instructions#
Curse of Instructions: Large Language Models Cannot Follow Multiple Instructions at Once
openreview.net/forum?id=R6q67CDBCH
The success rate of all the instructions is precisely explained by the success rate of individual instructions to the power of the total number of instructions.
That’s the “curse of instructions” (Harada et al., October 2024): individually easy steps compound into near-certain failure at scale. If a model follows any single instruction 95% of the time, 10 simultaneous instructions yield roughly 60% all-correct compliance. In practice, it’s worse. GPT-4o managed just 15% success with 10 simultaneous instructions. Claude 3.5 Sonnet did better at 44%, but neither is close to reliable.
When a prompt says “for each of 10 items, follow these 5 steps,” the model must satisfy 50 effective constraints in a single generation. The multiplicative decay means that individually easy steps compound into near-certain failure at scale. Unrolling into separate per-item calls keeps each call at 5 constraints, preserving the per-instruction success rate without cross-item compounding.
The IFScale benchmark (Jaroslawicz et al., July 2025) pushed this further, testing up to 500 simultaneous keyword-inclusion instructions across 20 models from seven providers. Even the best performer - Gemini 2.5 Pro - managed only about 69% accuracy at 500 instructions. More usefully, the study identified three distinct degradation patterns across model families:
- Threshold decay for reasoning models like o3 and Gemini-2.5-Pro: near-perfect performance until roughly 150 instructions, then collapse.
- Linear decay for models like GPT-4.1 and Claude 3.7 Sonnet: steady, proportional decline.
- Exponential decay for smaller or older models like Claude 3.5 Haiku and Llama-4-Scout: steep drops from the start.
This means the penalty for loop-style prompts depends partly on which model you’re using. Reasoning models tolerate higher instruction density before degradation kicks in. Smaller models degrade rapidly as instruction count grows.
Why It Happens#
The exponential compounding is a symptom. The disease is architectural.
Attention Sinks#
Researchers at MIT discovered that transformer models dump disproportionate attention onto initial tokens due to softmax normalization - a phenomenon they called “attention sinks” (Xiao et al., September 2023). A 2025 follow-up (Barbero et al., April 2025) traced the cause to a fundamental mechanism: LLMs use attention sinks to avoid over-mixing information across layers, and “their formation during training seems inevitable.” The original researchers proposed a practical workaround - StreamingLLM, which adds a dedicated placeholder token to absorb excess attention - but the underlying behavior is architectural.
In a loop-style prompt, the instruction block at the top becomes the attention sink while items in the middle are starved. Unrolling creates fresh attention sinks at each item’s instruction header.
Lost in the Middle#
“Lost in the Middle” (Liu et al., July 2023) demonstrated a U-shaped performance curve: models access information at the beginning and end of their context with meaningfully higher accuracy than information in the middle. A follow-up “Found in the Middle” (Hsieh et al., June 2024) traced this to an intrinsic attention allocation bias that persists regardless of content relevance, and proposed a calibration mechanism to mitigate it. The bias persists in practice - IFScale found systematic favoritism toward earlier instructions across all models tested.1 In a loop-style prompt processing many items, the middle items land in the degraded zone. Unrolling gives every item its own beginning and end.
Causal Masking and Prompt Repetition#
The most elegant piece of evidence comes from Google Research. Leviathan, Kalman, and Matias published “Prompt Repetition Improves Non-Reasoning LLMs” in December 2025. The finding: simply duplicating the entire prompt improved accuracy on 47 of 70 tested tasks with zero losses. On one task, Gemini 2.0 Flash Lite jumped from 21.33% to 97.33% - a 76 percentage-point gain.
The mechanism is revealing. In causal (left-to-right) attention, instruction tokens are processed before data tokens, meaning the instruction encoding lacks awareness of the data it must operate on. When instructions are repeated after the data - or, by extension, repeated per item - each instruction instance can attend to all preceding context, creating a richer signal. Critically, padding the prompt to equivalent length without repeating instructions produced no improvement, confirming the gain comes from information repetition, not length.
This has a direct implication for the loop question. Unrolling is not merely about reducing constraint count per call. It’s about giving each item its own copy of the instructions, positioned where the instructions can attend to the relevant data. The transformer’s causal attention architecture mechanistically favors this.
But there’s a wrinkle. The prompt repetition effect was “neutral to slightly positive” for reasoning models (5 wins, 1 loss, 22 neutral out of 28 tasks). Models that reason via chain-of-thought already perform an internal form of “re-reading” that mimics the repetition effect. This aligns with IFScale’s finding that reasoning models tolerate higher instruction density.1
The Cost of Unrolling: Instruction Drift#
So far, the case for unrolling looks strong. But unrolling has its own costs.
Repeating instructions N times increases total token count, and as context grows, the relative attention weight of the initial system prompt decreases. Research on instruction drift (Wen et al., October 2025) formalizes this as “turn-wise divergence from goal-consistent behavior over extended contexts.” The drift doesn’t accumulate without bound - it stabilizes at finite levels that can be shifted downward by lightweight interventions like goal reminders. But it means that aggressively unrolling a 50-item list into a single massive prompt could erode the very instruction adherence you’re trying to preserve.
This creates a tension:
- Loops suffer from exponential constraint compounding.
- Unrolling suffers from linear drift.
For small N, the compounding fix dominates; unroll. For very large N, drift may erode the gains. The crossover point - the sweet spot where you’d make a different design decision - is not precisely characterized in the literature, but the batch prompting research (Cheng et al., January 2023) suggests a ceiling: batching up to about 4 unrelated items retained quality, with degraded accuracy beyond that.
The Distinction That Actually Matters#
Nearly every study cited so far measures single-generation constraint satisfaction. ManyIFEval tests whether 10 formatting constraints are satisfied in one output.2 IFScale tests whether 500 keywords appear in one business report.1 Chen et al.’s multi-instance processing study (March 2026) tests whether 100 items are processed in one pass.3 The attention sink, lost-in-the-middle, and causal masking effects all operate within a single forward pass of the model.
But most people asking “should I unroll my loops?” aren’t writing monolithic prompts. They’re building agentic workflows where the model makes tool calls - reads a file, queries a database, edits a document - and each tool call creates a new generation boundary. In a typical agentic loop:
- Load guidance rule (tool call, new generation context)
- Read file (tool call, new generation context)
- Evaluate (reasoning step)
- Maybe edit (tool call, new generation context)
- Back to step 1 for next item
Each tool call resets the generation context. The agent isn’t trying to satisfy 15 constraints in one output - it’s doing 5 things, getting a response, doing 5 more, getting a response. The exponential compounding from ManyIFEval doesn’t apply because each generation carries only a handful of constraints. The positional bias effects are also mitigated, though how much depends on the harness - orchestration frameworks differ in whether and how they re-inject context between tool calls.
The prompt repetition paper implicitly confirms this: its effect is neutral for reasoning models because they already “re-read” internally via chain-of-thought.4 Agentic tool-call loops achieve the same re-reading mechanically - each iteration brings the instructions back into focus through the tool response cycle.
The Multi-Task Inference benchmark (Son et al., February 2024) tests and illustrates this boundary cleanly. When 2-3 closely related subtasks shared a single generation instead of being split apart, GPT-4 improved by up to 12.4%. The authors’ explanation: “looking at the next sub-task provides critical clues on the answer format for solving the previous sub-task.”
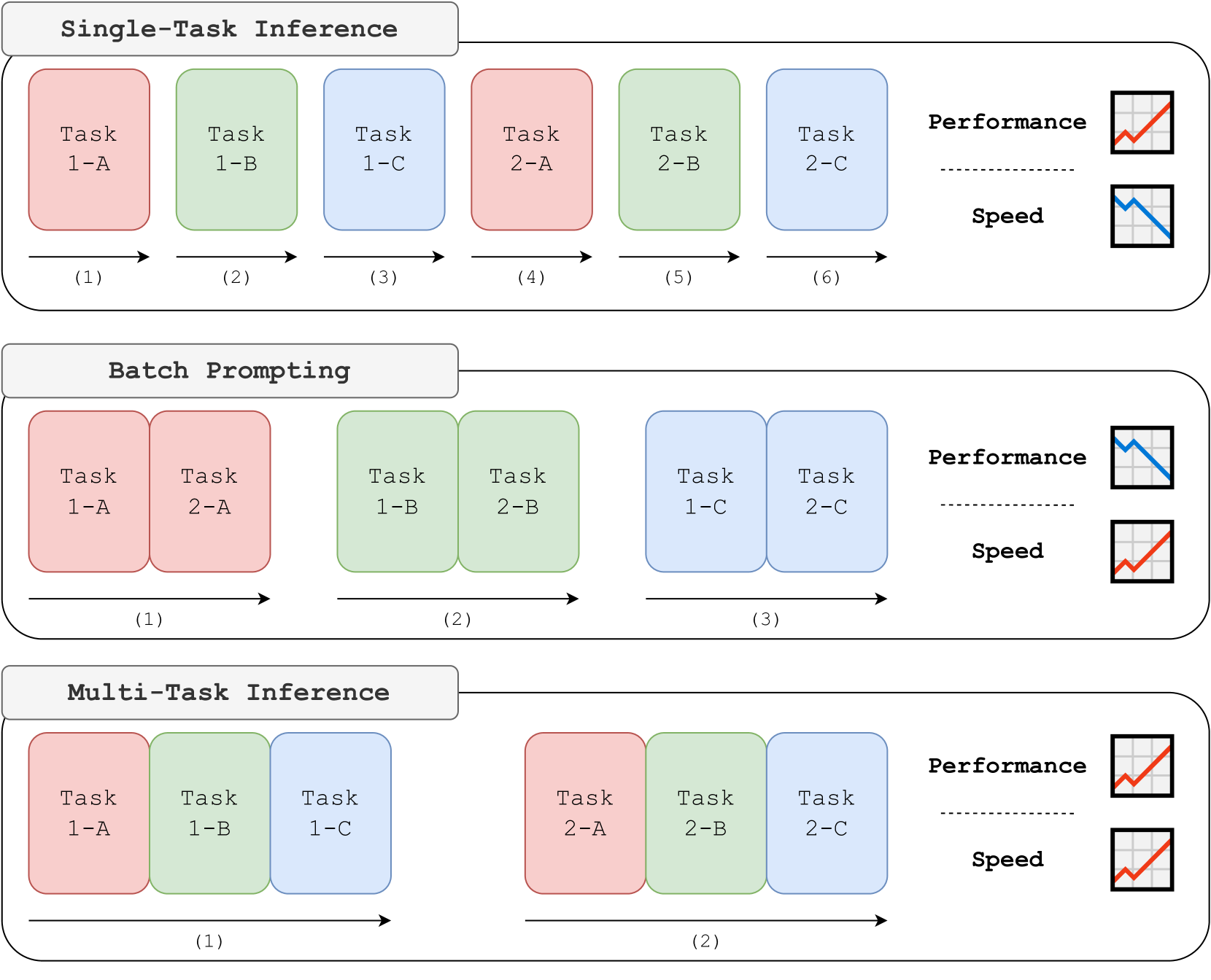
This is evidence about where to draw the generation boundary, not evidence for loops. Once you’ve partitioned work into per-item units, over-decomposing the steps within each item’s group can hurt by denying related steps access to one another’s context.
This doesn’t mean agentic workflows are immune to instruction-following failures. The AGENTIF benchmark (Qi et al., NeurIPS 2025) - the first benchmark specifically designed for instruction following in agentic scenarios - found that current models still struggle, even the best achieving only about 60% constraint satisfaction on agentic prompts averaging nearly 12 constraints each.5 Conditional constraints proved particularly fragile: over 30% of failures came from incorrect condition checking - the model failing to recognize whether a condition was triggered, not failing to follow the constraint itself. And meta-constraints - instructions that govern other instructions, like “prioritize X over Y” - were among the least reliable of all.5 The constraints-per-generation count still matters. It’s just that tool boundaries keep the per-generation count lower than what a monolithic prompt would impose.
There’s a deeper prerequisite for successful agentic looping, too. LLMs have effectively zero latent working memory - Huang et al. (2025) showed that LLMs function as “reactive post-hoc solvers” that reconstruct task state from context at every generation. They don’t hold a mental checklist; they re-derive one from the conversation history each turn. As that history grows, reconstruction degrades: open-weight models stop making measurable progress after about 6 steps,6 and roughly 23% of multi-agent system failures stem from premature termination, incomplete verification, or looping indefinitely.7 For iterative workflows, the fix is to externalize the iteration state - get the “what’s done / what remains” tracking out of the model’s head and into something it reads back explicitly.
Anthropic’s prompt engineering documentation reflects both of these takeaways. Their guidance explicitly advises externalizing the task list, and notes Claude’s reasoning as the reason why you don’t have to manually orchestrate multi-step processes anymore:
Use the first context window to set up a framework (write tests, create setup scripts), then use future context windows to iterate on a todo-list.
…
With adaptive thinking and subagent orchestration, Claude handles most multi-step reasoning internally. Explicit prompt chaining (breaking a task into sequential API calls) is still useful when you need to inspect intermediate outputs or enforce a specific pipeline structure.
The Real Question#
The most useful insight from integrating this research isn’t about loops versus unrolling per se. It’s that the relevant unit of analysis is the generation boundary, not the prompt boundary.
The research unanimously shows that within a single generation, constraint compounding is exponential and positional bias is real. The practical question is always: how many constraints am I asking the model to satisfy in this generation?
If the answer is “few, because tool calls partition the work,” loops are fine. If the answer is “many, because this is a monolithic prompt,” unroll. The real answer lurking under that decision is that while loops can sometimes work, unrolling - whether in the prompt, the harness, or within the model’s reasoning - is basically always being used for handling iterative assignments.
A Decision Framework#
For what it’s worth, here’s how I’d think about it:
Single-Generation Prompts#
No tool calls, one shot. You’re not writing code like this; this is maybe embedded in a production system, part of a data pipeline, or otherwise bundled up and just expected to perform inference once and return a result. Classifiers, judges, etc. In this situation, you’re often authoring the harness yourself, and so you get to choose what goes into a “generation” and how to glue results together for the prompt/context of subsequent generations.
These numbers come from different studies at different points in time, conducted against differing sets of models - they’re not absolute. Rather, when you are having to pick thresholds for your harness’ behavior, these numbers may help locate and guide your decision.
| Situation | Approach | Why |
|---|---|---|
| 1-3 related items needing cross-reference | Loop with structural markers | Cross-item context sharing may help |
| 4-6 independent items | Partial unrolling with per-item headers; repeat instructions at start and end | The prompt repetition sweet spot |
| 7+ items | Fully unroll into separate API calls | Exponential compounding dominates |
| Any count on smaller/older models | Default to unrolling | Exponential decay from the start |
Agentic Workflows#
Generation boundaries handle the compounding problem. But as noted above, the model still has to track what it’s iterating over - and it can’t do that reliably from context alone. Externalize the checklist.
| Situation | Approach | Why |
|---|---|---|
| Small set, few steps per item | Loop with tool calls | Generation resets handle compounding; short history keeps state reconstruction reliable |
| Large set or many steps | Externalize the task list; reduce the loop to <ol><li>pull task</li> <li>do task</li> <li>repeat</li></ol> | Models can’t reliably track “what’s done” in context alone |
| Complex per-item steps (5+ with branching) | Add structural markers within each iteration | Per-generation constraint count still matters |
| 20+ items in one conversation | Periodically re-inject core instructions | Guard against instruction drift8 |
Most agent harnesses provide some form of task-list tool for this; writing a checklist to disk can work just as well as third-party software solutions. The mechanism matters less than the principle: get the “what’s done / what remains” state out of the model’s head and into something it reads back explicitly.9
A personal rule of thumb: I’ll start capping any unbroken numbered instruction list at 4 items before a tool call, since the batch prompting research showed meaningful quality degradation beyond that threshold10… for now! We might expect this number to creep up as models get better, though it may not be from the underlying Transformer technology but from more-creative and effective behaviors layered on top of it.
In All Cases#
Use structural markers. Whether looped or unrolled, XML tags and markdown headings improve adherence by providing the kind of hierarchical boundaries that models have internalized from their training data. OpenAI’s GPT-4.1 prompting guide found that XML performed well for multi-document inputs while JSON performed particularly poorly.
<task index="1">
## Acme Corp
Evaluate this contract for renewal risk.
</task>
<task index="2">
## Globex Inc
Evaluate this contract for renewal risk.
</task>
If you must keep many items in a single prompt, three mitigations improve compliance:
- repeat the core instruction block after each item or at the end of the prompt4,
- use indexed structural tags for each item11,
- add a self-verification step asking the model to check whether it completed all items12
Think in Generations#
The transformer’s causal attention architecture mechanistically favors explicit, per-item instruction blocks over abstract loop constructs. This is not a prompting trick - it’s a consequence of how softmax attention, causal masking, and positional encoding interact. The research evidence for this is strong, converging from multiple independent programs.
But “always unroll” is an oversimplification that fails to account for how most people actually use language models today. In agentic workflows, tool-call boundaries act as natural generation resets that mitigate the very problems unrolling solves. The real skill is learning to think in terms of constraints-per-generation rather than constraints-per-prompt.
The research also suggests this isn’t something models will simply “grow out of.” Recent work on compositional generalization (Chang et al., May 2025) argues that for tasks requiring multi-hop reasoning - the logical equivalent of a loop - the training data requirement grows quadratically with token set size.13 The limitation is architectural, not parametric. Scaling model size doesn’t linearly improve loop handling.
So: unrolling works, the reasons it works are well-understood, and the situations where it doesn’t matter are equally well-defined. The question was never really “loop or unroll?” It was “how many things am I asking the model to hold in its head at once?” That question has a precise, architecturally grounded answer. It’s just not always the same one.
-
Jaroslawicz et al., “How Many Instructions Can LLMs Follow at Once?” July 2025. https://arxiv.org/abs/2507.11538 ↩ ↩2 ↩3
-
Harada et al., “Curse of Instructions: Large Language Models Cannot Follow Multiple Instructions at Once,” ICLR 2025. https://openreview.net/forum?id=R6q67CDBCH ↩
-
Chen et al., “Understanding LLM Performance Degradation in Multi-Instance Processing: The Roles of Instance Count and Context Length,” March 2026. https://arxiv.org/abs/2603.22608 ↩
-
Leviathan, Kalman, Matias, “Prompt Repetition Improves Non-Reasoning LLMs,” Google Research, December 2025. https://arxiv.org/abs/2512.14982 ↩ ↩2
-
Qi et al., “AGENTIF: Benchmarking Instruction Following of Large Language Models in Agentic Scenarios,” NeurIPS 2025. https://arxiv.org/abs/2505.16944 ↩ ↩2
-
Ma et al., “AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents,” NeurIPS 2024. https://arxiv.org/abs/2401.13178 ↩
-
Cemri et al., “Why Do Multi-Agent LLM Systems Fail?” 2025. https://arxiv.org/abs/2503.13657 ↩
-
Wen et al., “Drift No More? Context Equilibria in Multi-Turn LLM Interactions,” October 2025. https://arxiv.org/abs/2510.07777 ↩
-
My own prompt ruleset, Niko, applies several of these principles: externalized task files for set-tracking, forced file re-reads for instruction re-injection at phase boundaries, and explicit STOP gates as generation boundaries. ↩
-
Cheng et al., “Batch Prompting: Efficient Inference with Large Language Model APIs,” EMNLP 2023. https://arxiv.org/abs/2301.08721 ↩
-
Anthropic, “Use XML tags to structure your prompts,” Claude API Docs. https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/use-xml-tags ↩
-
OpenAI, “GPT-4.1 Prompting Guide,” OpenAI Cookbook. https://cookbook.openai.com/examples/gpt4-1_prompting_guide ↩
-
Chang et al., “Characterizing Pattern Matching and Its Limits on Compositional Task Structures,” May 2025. https://arxiv.org/abs/2505.20278 ↩